Introduction
Une vaste bascule de l’offre technologique des fournisseurs de microprocesseurs vers des processeurs 64bits s’est opérée depuis 15ans. Cette transition a été opérée en douceur en assurant une compatibilité 32bits au niveau matériel comme logiciel. A partir de 2020, la grande majorité des machines disponibles et maintenues seront uniquement 64 bits.
Clariprint est une solution d’élaboration et d’optimisation de gamme de fabrication pour l’imprimerie. Le logiciel est écrit en langage Claire, spécialement conçu pour écrire des algorithmes d’optimisation. L’environnement CLAIRE est seulement disponible en 32bits. Nous recherchons plusieurs scenarios dont celui consistant à essayer de passer l’environnement CLAIRE en 64 bits tout en gardant des performances raisonnables.
Nous constatons donc :
- L’environnement de développement dédié aux algorithmes hybride CLAIRE n’est pas disponible en 64bits.
- L’impact sur les performances du passage au 64 bits est peu documenté, notamment pour les algorithmes manipulant beaucoup de données
- Quelles opportunités sur des améliorations de performance : taille des problèmes, temps de réponse …
Etat de l’art
L’environnement CLAIRE (Combining Logical Assertions, Inheritance, Relations and Entities) a été écrit par Yves Caseau (ENS) en 1994. Plusieurs évolutions l’on mené à une certaine maturité comme outil scientifique en 2000 avec l’apport notamment de François Laburthe (ENS).
Architecture CLAIRE

Noyau (kernel):
- Fonction de base du système Claire
- Objets système, méta représentation
Ramasse miette (Garbage collector)
- Gestion de la mémoire
Interprète (Reader):
- lecture du code et création d’une méta-représentation
- exécution du code méta-représenté
Optimiseur de code (source to source optimiseur)
- recherche des motifs dans la méta-représentation susceptible d’être modifié pour de meilleure performance d’exécution
Compilateur C++ (compiler)
- Génère du code C++ à partir de la méta-représentation fournie par l’interprète.
Travaux de recherche de références
Claire 2 & 3 : Apple Macintosh / Code Warrior (Yves Caseau – 1994)
CLAIRE 2 a été créé sur la plateforme MacOS9 avec le compilateur Code Warrior. On peut attribuer une partie de la gestion mémoire actuelle à cette période ou les systèmes d’exploitation étaient moins robustes, et moins efficients sur les processus d’allocation. Par ailleurs ces mécanismes étaient nécessaires pour assurer les fonctionnalités spécifiques à CLAIRE, comme le raisonnement hypothétique, les règles et la gestion automatique de la mémoire.
Claire 2 embarqué / Eclair (A constraint optimization framework for real-time applications) .
Une version expérimentale de CLAIRE2 a été développée dans les laboratoires de Thomson CSF (Thales). Cette version était expurgée du code C++, pour fonctionner dans des environnements ne disposant que de compilateur C. Le noyau permettant principalement de faire fonctionner une bibliothèque de résolution de contraintes : Eclair. Eclair a évolué vers la bibliothèque CHOCO, une des plus utilisées à ce jour.
Claire 3 / Microsoft Windows NT
Début 2000, au sein des laboratoires du eLab de Bouygues SA, CLAIRE 2 et CLAIRE 3 ont été portés sur Windows NT. Il s’agissait d’un portage simple, CLAIRE restant proche des normes POSIX correctement supportées par Windows NT. L’apport d’un environnement relativement stable (Windows NT) couplé à du matériel abordable, cette version a été utilisée sur de nombreux projets de recherche et industriels chez Bouygues, TF1, Thales et Expert Solutions. Cette version a facilité l’intégration à des outils existants via des bibliothèques partagées (DLL).
Claire vers Java (2002 – Thèse – François Xavier Josset – Univ. Versailles St Quentin)
En collaboration avec le eLab de Bouygues, François Xavier Josset, a tenté de porter Claire sur Java. En écrivant un nouveau noyau en Java et un compilateur Claire-Java, les équipes souhaitaient bénéficier des grande facultés de portabilité de Java, d’intégration aux systèmes informatiques en pleine expansion. D’importantes difficultés n’ont pas permis au projet d’atteindre les objectifs. Les travaux ont révélé une gestion mémoire (garbage collector) peu performante, et une efficacité d’exécution de code aléatoire. Toutefois, une partie des outils créés pendant ces travaux concernant la métrique qualité ont inspirés des travaux en cours chez Expert-Solutions.
Linux / Unix (Yves Caseau, Sylvain Benilan, Xavier Péchoultres)
Début 2000 sous l’impulsion d’Expert Solutions, un portage de CLAIRE vers les environnements Unix & Linux a été mené en collaboration avec Yves Caseau. Cette version a été adaptée à de nombreux environnement unix 32bits (Linux, MacOSX, SunOS ..). Elle est au coeur de plusieurs outils commerciaux.
Claire 3.4 : un GC Dynamique (2011 – Xavier Péchoultres, Laurent Rebière)
En 2010, afin de mieux gérer des algorithmes ayant des besoins mémoires très variables, l’équipe d’Expert Solution a effectué un travail de recherche sur les différents algorithmes de gestion d’allocation mémoire.
Calcul distribué (2013-2015)
Afin de réduire les temps de réponses, Xavier Péchoultres & Laurent Rebière, ont effectué des recherches sur l’implémentation de mécanisme de distribution de calcul au sein d’algorithmes de branch and bound. Des gains considérables ont été observés.
Claire Swift (2017 – Yves Caseau)
La plateforme Swift a été créée en 2014 par Apple. Elle propose un ensemble complet de développement autour d’un langage moderne, disponible en source libre. Séduit par le système, Yves Caseau a tenté de porter Claire, sans succès jusqu’à présent, le projet semble abandonné.
Alignement Mémoire
Notes d’IBM pour l’architecture Power (2005): https://developer.ibm.com/articles/pa-dalign/
Mise en évidence de l’impact (2017) : https://fylux.github.io/2017/07/11/Memory_Alignment/
Un environnement 64 bits
Verrous technologiques
Le passage en 64 bits de l’ensemble de l’environnement est un véritable défi. Les différentes tentatives de transfert de la plateforme initiale ont généralement été des échecs, soit en terme fonctionnel (possibilité de retranscrire les concepts dans la nouvelle plateforme) soit en terme de performances.
Nous avons donc tenté de caractériser les éléments clés du projets :
- CLAIRE est écrit principalement en Claire : nous devons disposer d’un compilateur fonctionnel pour compiler CLAIRE.
- Correspondances des types : Le noyau de CLAIRE utilise des mécanismes permettant d’accélérer des traitements, fortement liés à la structure interne des types simples. Les types de données en 64bits sont moins homogènes que les types 32 bits (modèles LLP64, LP64, ILP64).
- Alignements mémoires
- Impact de l’augmentation du volume de données sur les performances. Nous avons démontré lors de travaux précédant la forte corrélation des performances (temps de calculs) avec la bande passante mémoire effectivement disponible entre le processeur et la mémoire vive.
Hypothèse à vérifier
Nous constatons une combinatoire sur les options à comparer :
| Modèles | Taille entier | Type GC | Alignement mémoire |
| 1 – 32MM | 32bits | Monolithique | Manuel |
| 2 – 32MA | 32bits | Monolithique | Automatique |
| 3 – 32UM | 32bits | Unitaire | Manuel |
| 4 – 32UA | 32bits | Unitaire | Automatique |
| 5 – 64MM | 64bits | Monolithique | Manuel |
| 6 – 64UM | 64bits | Unitaire | Manuel |
Avec des entiers en 64bits l’alignement mémoire est automatiquement assuré. Il ne sera pas nécessaire de le tester.
Méthodologie
Réécriture du noyau et compilateur en rendant paramétrique la correspondance de type.
Nous avons essayé de réécrire un noyau et un compilateur en ajoutant des routines permettant de pouvoir plus aisément tester différentes configurations de correspondances entre les types CLAIRE et les types C. Claire repose sur quatre types de base : oid (adresse), integer, float, string.
Le noyau CLAIRE utilise une méthode de masque permettant de différentier les données contenant une adresse d’objet (oid) et les entiers. Cette identification permet aux différents organes de contrôle d’identifier directement ces types sans faire référence à la méta représentation. Le gain en performance est alors évident, surtout lors du parcours du ramasse-miette.
Ces masques sont créés sur les bits de poids fort, hors si les données comparées sont hétérogènes, cette méthode directe ne conviens plus. Une nouvelle méthode est donc nécessaire pour supporter les modes 32**, qui disposent donc d’oid en 64 bits et d’entier en 32bits.
CLAIRE fait appel a des interfaces systèmes, hors si lors du passage au 64 bits, les opérandes de types adresses ont naturellement respecté la nouvelle taille, le passage des autres paramètres, notamment les entiers (int, long), n’est pas aussi homogène. De nouvelles précautions sont donc à prendre.
Lors de l’implémentation de ce nouveau noyau, nous avons notamment rencontré des problèmes avec la gestion de l’alignement mémoire. Claire disposant d’un mode de fonctionnement double, interprété et compilé, les deux pouvant agir en même temps, la méta-représentation doit être fidèle à la représentation créée par les compilateurs.
Apres plusieurs essais, nous avons un candidat sérieux qui a passé une première batterie de tests opérationnels. Il est pour l’instant validé que pour une seule stratégie de typage et un seul modèle de données 64bit : 64MM.
L’étape suivant est de créer un environnement supportant le mode 32MM, ce qui permettra d’effectuer des arbitrages sur l’opportunité de tester les autre modes 32**.
Validation des différentes correspondances de typage.
Types simples
La prochaine étapes consistera à créer plusieurs prototypes avec plusieurs correspondances de typage.
Types complexes
Les différents environnements d’exécution C++ ont des contraintes d’alignement des données. Cela conduit à :
- une variation sur la mémoire effectivement allouée, donc la quantité manipulée et par conséquent les performances.
- Tenir compte dans la méta-représentation et les optimisations de code des éventuels alignements.
- Alignement : certain environnement demande à aligner sur des adresses 64bits les données sur 64bits. Cela conduit parfois à allouer plus d’espace.
Struct mastruct { int a ; double float } => sizeof(mastruct) != sizeof(int) + sizeof(float)
Représentation en mémoire :
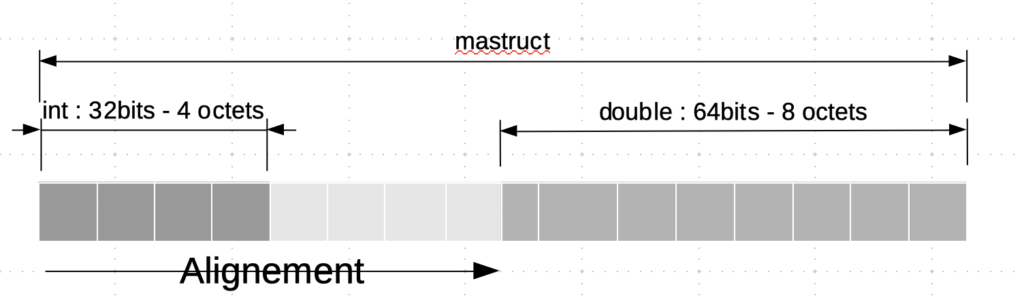
Une voie de recherche concerne la réordonnance des variables membres d’une classe lors de l’optimisation de code, mais nous ne connaissons pas actuellement quel peut être l’impact de ce genre d’opération.
Mise en place de jeux de tests de performances
Nous allons mettre en place trois catégories de jeux de tests.
Tests d’allocation
Ce sera un pur test d’allocation permettant de comparer les performances en allocation mémoire, exemple :
maclass <: ephemeral_object(a:integer,b:float,c:integer,d:boolean) for i in (1 .. 10000) (for j in (1 .. 10000) maclass())
Nous effectuons ici deux boucles imbriqués allouant une instance de la classe « maclass ». Nous pourrons comparer plusieurs définitions de classe incluant des problèmes potentiel d’alignement.
Pour créer un problème d’alignement, il faut placer un champs de type 64 bits à la suite d’un champs 32 bit d’index pair.
Test de performances standard
Un jeu de test basé sur la série de Stanford (Stanford Benchmark Suite).
Tests en condition réelles
Nous disposons de plusieurs milliers de jeux de tests basées sur des données clients. L’objectif ici est de construire un système de benchmarking permettant de comparer des version de nos applications et donc ici de CLAIRE. Ce système est à créer.
Conclusion
Fin 2018, nous ne disposions que d’un prototype ayant passé les premiers tests fonctionnels en mode 64MM. Une fois les autres prototypes réalisés, une campagne de test de performances permettra d’évaluer les hypothèses d’améliorations.